The Git for APIs

Aidan Cunniffe 2020-12-09
To everyone who has tried Optic, contributed code, told us your stories, written about the project, and helped us chart our course — we (the maintainers) want to say thank you! We know it’s been a crazy year and API tools are not the most important happening in the world right now. Still you’ve made the time for our open source project, and in doing so, helped keep us all employed. We can’t thank you enough for giving our team the opportunity to work on these problems. Thank you, sincerely.

One Big Graph
Whether we like it or not, every piece of software we build is now part of a distributed system. Internet archeologists and techno-ecologists from the future will peel back the Docker layers and no doubt write about how, in the 2010s, everything became part of one giant dependency graph — a grand ecosystem of systems.
Now we all have stories about a time we were trying to code against an API with poor documentation or, weeks later, how an unannounced change in that API brought down the application we were building. We’ll never forget that time our team broke an important consumer with minor API changes, and especially not that Friday afternoon we took out all the old versions of our product’s mobile app.
In the before times we shipped our code, alongside our dependencies. Most views were rendered on the server-side, and we controlled all the consumers. The monoliths were big, self-contained universes. New versions of libraries would come out, but there was no urgency to upgrade — you could plan time in your development cycles to upgrade or just pin yourself to x.y.z until it would no longer link.
When we depended on libraries, additional code that shipped along-side our applications, we could use Git tags and package managers to tame the chaos. In these times, it’s not so simple.
The API Problem
Dev and I spent our first months working the ‘API problem’ in design sessions with the community, and spinning/throwing out several POCs to explore our more abstract hypotheses. We learned a lot, we tried a lot, we deleted the entire codebase more times than you’d expect.
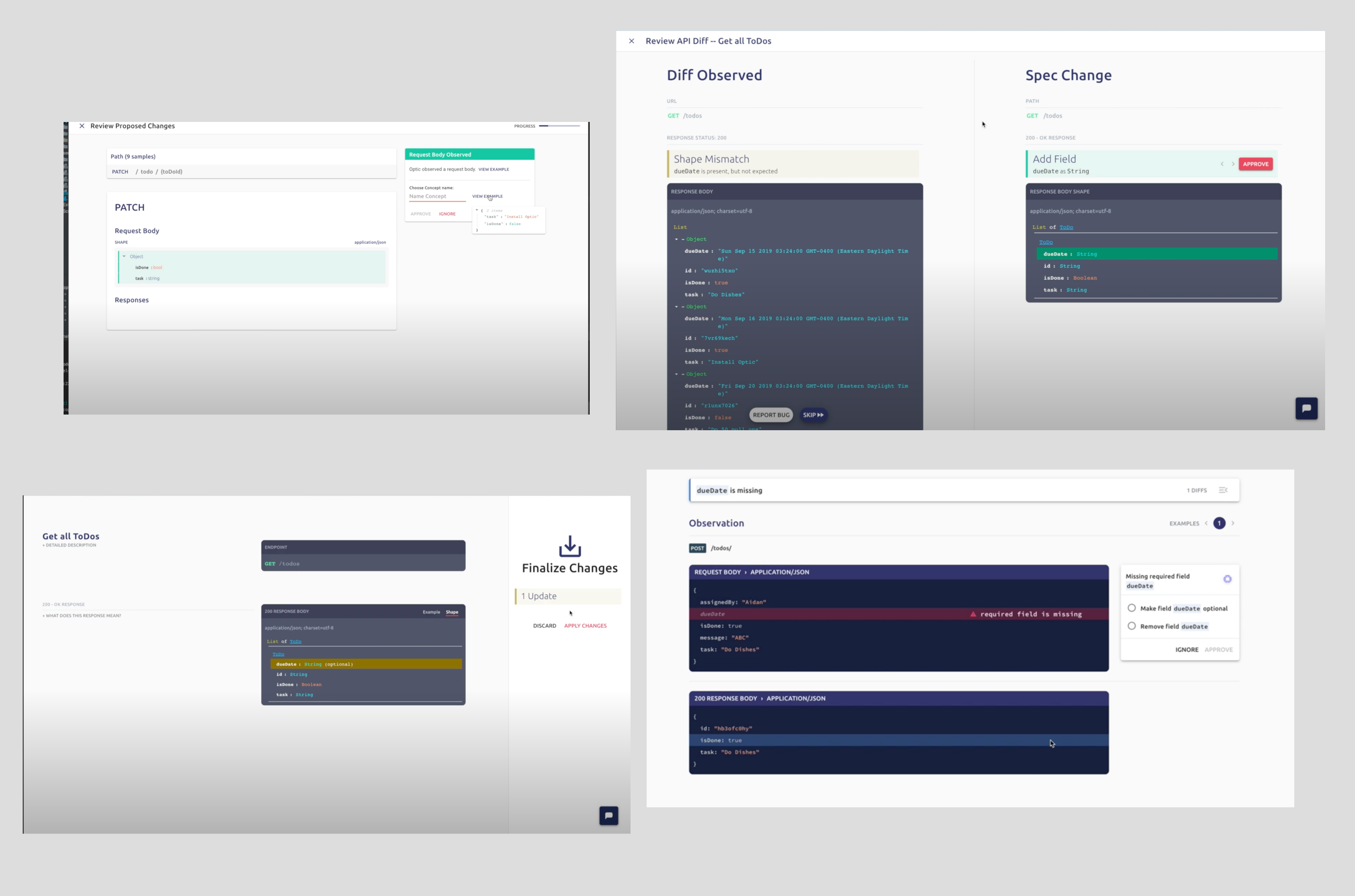
We stepped away from that period with a strong conviction. The challenges we all experience managing our APIs can be reduced, as big problems often can be, to a single problem: when it comes to APIs, we have been versioning the wrong thing.
Teams that build and publish APIs, whether they’re internal-only, public, or built for specific partners all broadly want the same guarantees. API teams want to know that every change (intended or accidental):
- is detected,
- accurately documented,
- and reviewed by their team, before it is deployed to consumers
In an ideal world there would be a tab in every Pull Request next to Files Changed called APIs changed that magically presented an accurate API changelog:

In that world, reviewers have all the context they would need to approve the PR or request changes. There is no need to run the code in their head and reason correctly about the changes introduced, it's all made obvious: “Oh if we merge this code, it’s going to change the API in a way that breaks old versions of the mobile app. Changes requested!“.
Today's API teams use a patchwork of manually cultivated contract tests, API specifications and homegrown diffing tools to achieve some of these capabilities, but most teams experience API tools that are not nearly as mature as Git + code collaboration toolchains they are accustomed to using.
On the other side of the equation, developers who are consuming APIs want (in addition to their specific business requirements):
- accurate API documentation that’s easy to work with
- advance notice about an API changes that are going to affect their usage patterns
- consideration of their use cases when the API producer is planning changes. “Make my use case easier, if not easier, at least don’t break it or make it harder.”
Again — all of this is possible. API teams can invest heavily in documentation, promote good practice around avoiding breaking changes, and take extra effort to scour logs and learn how their consumers use their API. So many teams have done good work here. The community has built and made mainstream great specifications, a set of best practices, and tooling to help manage all this complexity. And there are some real exemplars, teams that do all of these things well from which the community can draw inspiration. When teams make the big investment, build the practice, and earn these capabilities — it works, it really works (See Stripe, Twilio, GitHub). Bringing these capabilities to the masses as a developer friendly toolchain for API versioning is a meaningful problem to solve.
Being Git
I remember sitting in a library years ago when I was first learning to program. A good part of that evening was spent emailing source code back and forth with my friend. Neither her nor I had learned how to use Git properly so this email dance was our version control practice. It was state of the art — given what we knew.
We were not using Git, we were “being Git”. And we sucked at it....I had to keep a model of what I had changed in my head (working copy), try to understand her (working copy) and then copy/paste code between the two versions every few hours (manual merging). I made mistakes, I erased some of her code, I definitely broke things that had been working before.
Discovering Git days later was a promethean moment — mythology pun notwithstanding, we were now cooking with fire.
Since then, the closest things I’ve experienced to that feeling of “being Git” have been API related. I see it everywhere now:
- it’s the late night Slack message soliciting an explanation of how to format a query parameter
- it’s thinking “hmm” after realizing my specifications are always more lines than the APIs they describe
- it’s that lost feeling I have when visually comparing a JSON body to a specification to check if I’ve coded the endpoint behavior properly. (This often includes cursing at curl for not having an ‘alphabetize fields’ flag)
- it’s trying to parse a Git diff for 12k lines of OpenAPI to understand the blast radius of a change my peer is proposing
In a world of distributed computation and independently evolving systems, understanding how all the APIs work, and knowing when they change, has become an essential facility. This versioning problem is adjacent to source code management. We have good tool chains for managing code changes (Git), but when it comes to the behavior of that code we rely on tribal knowledge, manually written and updated specs, and incomplete tests.
That is why we’re building Optic, why we’ve chosen to make it free + open source, and have committed ourselves to building the most developer friendly tool chain for versioning the world’s APIs.
Optic as the Git for APIs
Imagine you’re building new API endpoints. You tear through user stories and have fun writing the logic to handle your business cases. Not once are you worried about how you will get the code you’re writing to your teammates. That’s just a few Git commands and a Pull Request away.
But how do you share the new endpoints with the team? Most engineers do not enjoy writing documentation. We don’t want to break our flow and start documenting — especially if the API’s design is still in-flux. Why isn’t there a quick command we can run to document all the new endpoints?
That’s a job for the Optic CLI which makes documenting your API and updating its specification as easy as using Git.
In the example above, you’d just run api status and you’ll see Optic detected the new, undocumented, URLs:
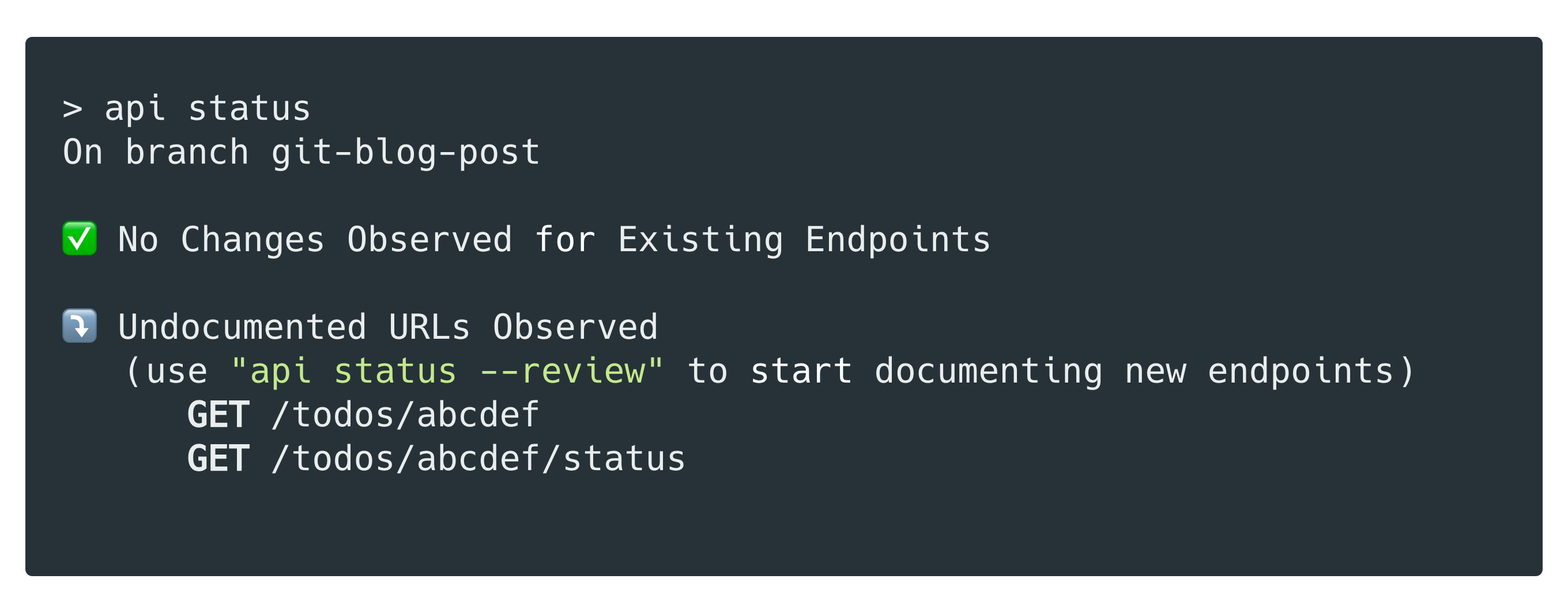
Open your local Optic client and use it to add the new endpoints definitions to your specification:
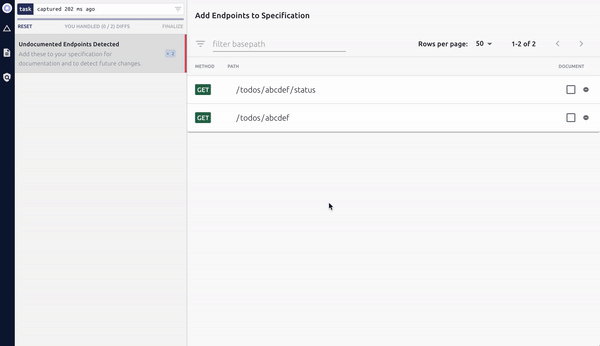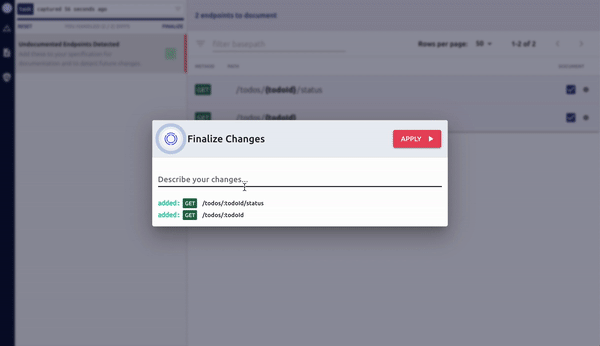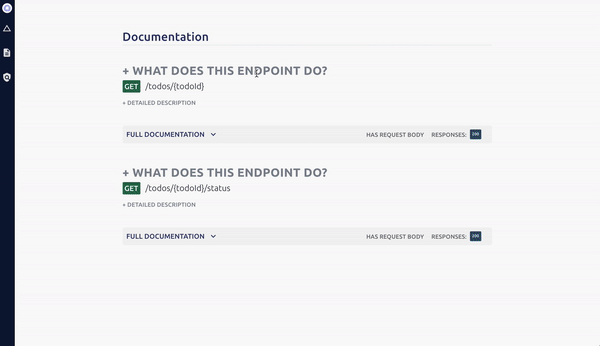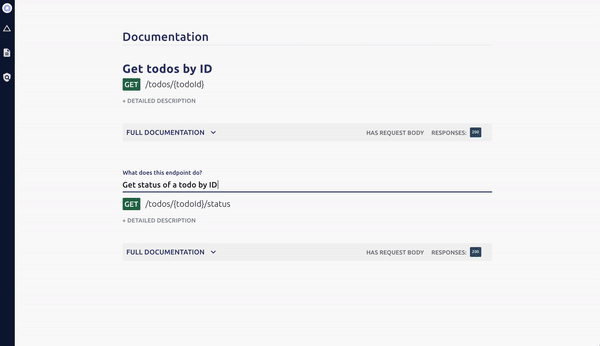
Then commit your code, and open a Pull Request. Optic’s GitBot ensures teammates can see the API changes this PR introduces, not just the code it changes.
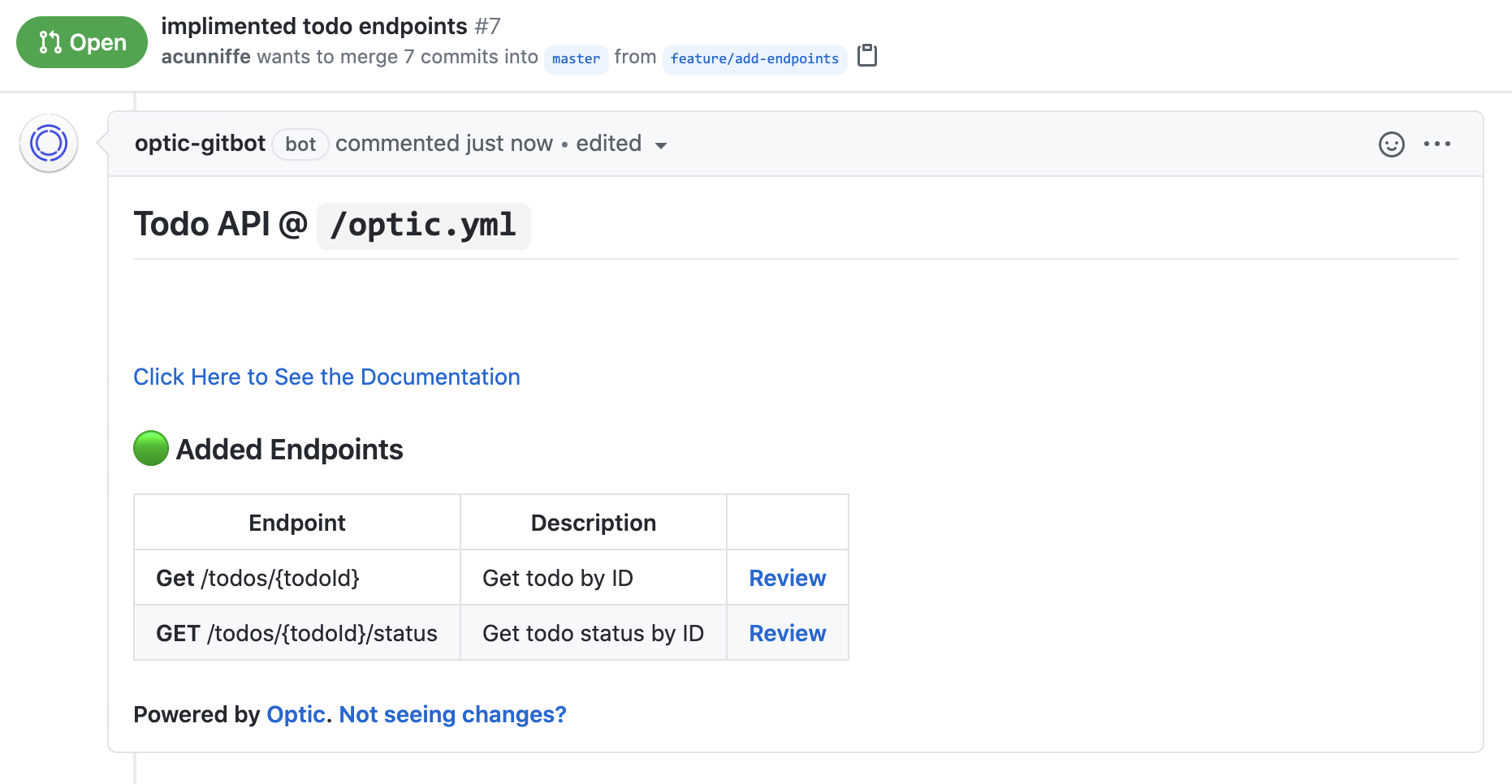
You did not have to write a giant YAML file or add annotations to your code to get these new endpoints documented.
And when someone on your team checks-out the code and starts working on a new feature, they too, can run api status and see if they’ve introduced to the API’s contract.
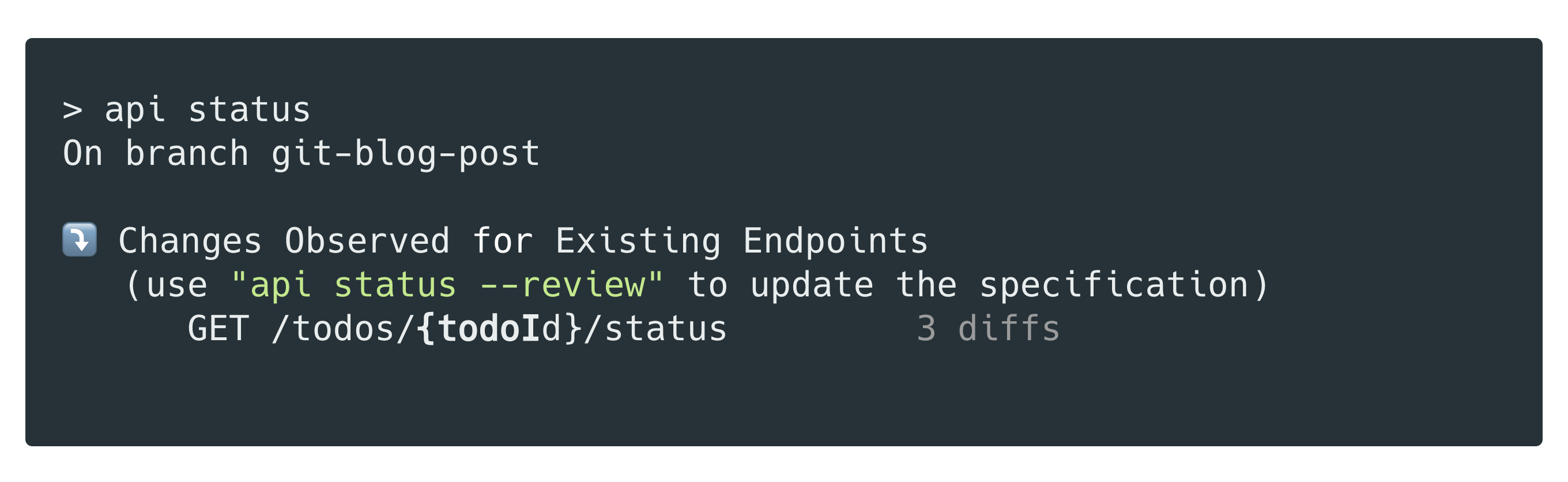
The Optic client detects all the changes and lets you ‘Approve’ them, resulting in an update to your specification. Patching the specification is handled by Optic, and the resulting changes are presented in the Pull Request for your team to review.
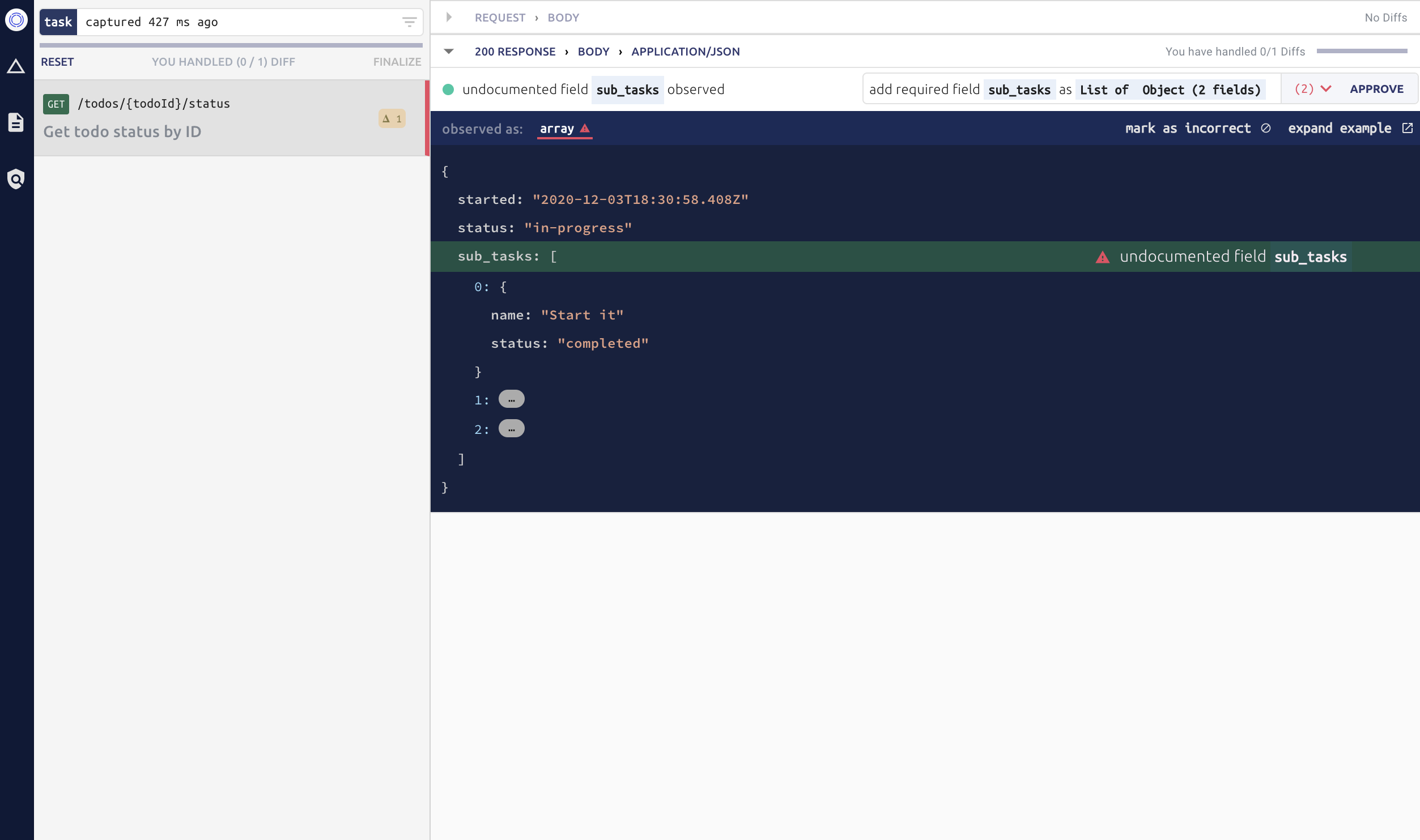
Optic will also help you catch bugs — maybe you started leaking the social-security-number in one of the response bodies. You can go fix the bug and watch it disappear from the Optic Client OR if you approve this change it’s now part of the PR for someone else on your team to (hopefully) catch in review: “Jason proposed these changes....returning social-security-number...”
Design First with Optic
We are getting help from users and people in the API community as we explore how Optic will support both design-first and code-first workflows.
In practice, we've found every team does a bit of both, and that's ok. What matters is that every API change is reviewed by the team before it gets deployed to consumers. By including information about the maturity of each part of your API spec, Optic can provide the right feedback at the right time. Each diff can be interpreted depending on the context. Either Optic will guide the engineers towards implementing the design, help them detect accidental changes to the API, or document the API changes they've made so they can ask their teams to review/approve them.
There has not been a way to distinguish between the parts of an OpenAPI that are marked as "in-design", already "approved", or known to be "implemented". Optic can distinguish between the maturity of each part of your spec and that opens up the new workflows we've been exploring:
If your team designs and proposes changes before implementing them in code, that's fine. The developers tasked with making those changes will see Optic's diffs re-framed as todos: "You still need to change address from a string an object with [this] shape". We imagine an automated flow that feels like test-driven development, where Optic guides developers in real-time towards coding the designed behaviors correctly. Every time it observes a new request to the endpoint you're working on, it'll update the remaining todo list until you fully implement the changes.
When developers change the implementation to meet new requirements, it should be easy for them to also update the spec (code-first). As long as Optic presents these changes in PRs, the team can discuss the proposed changes during code review long before the changes get deployed. Making changes in the implementation first is fine, provided releasing those changes to the API is gated by a code review.
This is all just a big synchronization problem. Sometimes it makes sense to pull the spec towards the code, other times it makes sense to guide the code/developers towards the spec. We're really excited to build an experience that brings teams the best of both worlds.
🚧 If you find this work interesting, set up a meet the maintainers call (opens in a new tab). Everything is on the table now, and you have the opportunity to join the design sessions and influence how these features get built.
How it works: The API Diff
Almost a year ago, we released the first version of Optic that was backed by API traffic diffs (opens in a new tab). It was rough around the edges, but it worked.
This early version of Optic would compare all the traffic it observed during local development against your API specification (like a validation proxy) and emit a set of diffs between that traffic and the current specification.
The differentiating capability was that, in addition to diffs, the tool provided suggested updates to the API specification.
For example the diff unexpected field X would pair with a suggestion to Add new field X. The user could quickly review and approve any of these suggestions and Optic would do the work of patching the specification for them.
In Optic, your working copy is the traffic observed by the tool. That traffic can produce diffs when compared to the current specification, and those diffs pair with suggestions that can be ‘staged’ as changes to the specification.
This workflow quickly showed promise. Users found it to be an easy and natural way to keep their API’s behavior in-sync with their specifications. Users were already looking for diffs manually and patching the specs themselves — but only sometimes, and often long after a behavior change had actually been introduced.
Users thought of Optic as good, ‘low-stakes’, automation for maintaining accurate specs. Optic would surface behavior changes and automate updates to the spec, but nothing happened without their say-so.
The community’s excitement for the project showed us we were onto something, so we doubled down and got to work making the experience of using Optic really sharp.
Making Optic Developer Friendly
Landing a new workflow that developers enjoy using is a tall order -- it does not happen overnight. A failure mode I see building these kinds of tools is thinking about your new workflow’s comparative advantage rather than measuring and improving the experience of using your tool. “This is already so much easier than manually writing OpenAPI...” we could have said, before moving onto the next shiny thing. We didn’t.
Improving the Optic Client
The Optic Diff UI has been through several major changes since it was released at the end of last year. I talked at length about these changes and what insights informed them when Optic was featured on Software Engineering Daily (opens in a new tab).
The latest version (no surprise) looks like a Git client and is currently being tested by some of the power users in pre-release. It’s a lot faster, and shows a more zoomed out view of your API. Lots of consideration has been made to make the next steps obvious, and the amount of work Optic asks you to do, deterministic. The improved predictability, control and performance should help developers quickly jump in and out of the Diff UI just like they do with a Git client.
Running Optic Everywhere
Teams get the most value from Optic when it becomes part of their existing code review process. When PRs include both code changes (thanks Git) and API changes (thanks Optic), reviewers can confidently +1 the PR or request changes. For this magic to work, Optic needs to be running in the individual development environments or locally.
This was a hard requirement to take on. We had to work with any kind of API, run fast on commodity hardware, and be portable just about anywhere. It would have been much easier to just run a hefty server in AWS and stream API traffic there, but who on earth would want to send their traffic to us? And how would we stay open source if all the magic had to run on our cloud?
It did not take long before large teams started throwing gigabytes of traffic at Optic, and our original MVP-quality diff engine would choke, often taking multiple minutes between the last user action, and presenting the next. The fact some users were still willing to use the tool and would make use of these ‘intermissions’ as their coffee break reinforced the importance of what we were building and gave us a lot of appetite to fix these issues.
Optic’s diff engine had to be completely rebuilt in Rust. It was a big undertaking and slowed down our roadmap for a few months, but the payoff was huge. Some users would need to run gigantic diffs several times a minute -- which was impossible when some of these huge batches of traffic took 16 mins to run on commodity hardware. With Rust, these same diffs take less than 1 second now (1000x speed up).
With this porting to Rust, the diff engine has been hardened into a much faster, far more reliable component, that delivers on being able to "run everywhere".
Check out the code here (opens in a new tab)
We’ve seen teams use the new engine to document APIs with 250 endpoints in under an hour. They end up with 15k+ lines of OpenAPI managed by Optic, and most of their time is now spent naming their endpoints instead of waiting for Optic (we can’t help you there).
This level of performance opens up so many design affordances — and makes familiar flows from Git like api status feasible to build within Optic.
You can try the new engine in the @beta channel -- it's been there ~3 weeks, and will be mainstreamed as soon as the remaining bugs get squashed.
Evolvable API Specifications
Early on we realized that modeling how an API changes over time is a really important part of the story — think API specifications, but with a time axis. API change management is all about the changes — it’s right there in the name. However, it’s not easy to compare any two versions of a spec to determine what’s actually changed. It's also hard to represent both the API's actual behavior, and the proposed changes a team is building towards in the same specification. How do you distinguish the current state of the API from the 'designed' (but not implemented) state?
To address these issues we built the Changelog spec, a CQRS/ES inspired ledger of every change that has ever been made to the API. It has some cool properties worthy of an entirely separate post (opens in a new tab) and a live demo (opens in a new tab). Look out for other vendors and OSS projects that are working to improve + adopt it next year.
What's Next
Thank you all for being a part of this journey with us. We're going to continue to make real this vision of Optic, and we're excited to bring you our takes on the G̶i̶t̶Hub for APIs as we build out more of the platform in the new year. These are hard problems to work on, and we could not do it without your support and feedback. Our team is driven by the mantra "esse quam videri" -> "to be, rather than to seem". We'll keep listening, iterating, and doing our best to live up to our own hype and solve these problems well.
If you're new to Optic, hop in a quick call with us -- what better way to start off the new year (opens in a new tab).
Getting Involved
People often ask us how they can contribute to open source projects like Optic. You can write some code, but it's not just about writing code. There are many ways to contribute and sometimes people share an "idea contribution" with us that has completely changed how we think about a problem and feature we build.
💬 Share your stories + ideas on GitHub (opens in a new tab)
🎺 Write a blog post (opens in a new tab), or tweet about Optic.
🔨 Write some code! Discuss some areas to contribute during office hours (opens in a new tab)
💼 Join the Team! (opens in a new tab) We're looking for Product-Minded Developers who like to talk to users, design+plan their own work, and build great experiences end-end. If that's you, we'd love to meet (opens in a new tab)
Want to ship a better API?
Optic makes it easy to publish accurate API docs, avoid breaking changes, and improve the design of your APIs.
Try it for free